システムデザイン分野
クラスタリングおよび文書データ解析の研究
-

-
内山 俊郎
教授
Toshio Uchiyama
キーワード
トピックモデル、情報理論的クラスタリング
研究を始めるために必要な知識・能力
データ解析により興味深い結果を得ることを「面白い」と思うことや、解析した結果を可視化したり、文章化したりするのが重要だと考えることを求めます。また、線形代数について知り、プログラミングができることが望ましいでしょう。これらについて理解を深めることは、入学後で良いと考えます。
この研究で身に付く能力
私が取り組んでいる文書データ解析の研究について、学ぶこと(知ること)ができます。これは、関連する基本技術について、学ぶことも含みます。たとえば、クラスタリング、機械学習の1つである競合学習、解析結果の可視化などです。また、研究では論理的に文章を組み立てることが重要です。簡単ではありませんが、学ぶ姿勢があれば、身につけられるでしょう。
研究内容
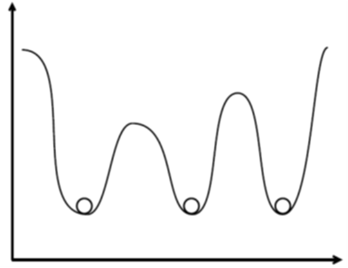
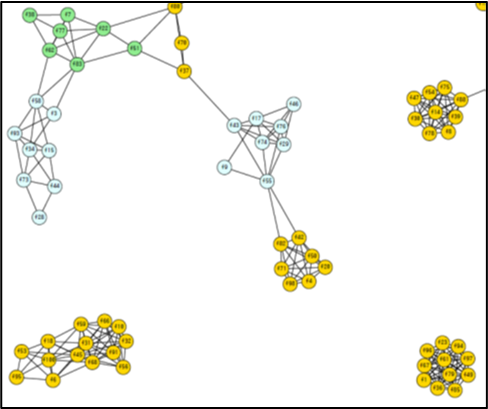
現在取り組んでいる、「トピックモデル」を用いた文書データ解析について説明します。世の中には、至るところに膨大な文書が存在し日々増えており、どのような文書が存在するのかを人間が読んで把握することは困難です。機械学習の1つである「トピックモデル」(2003年にBleiが発表したものが代表的)を膨大な文書データに適用すると、どのようなトピックが存在するのかを発見することができます。これは、カテゴリなどを与えて分類するのではなく、カテゴリ自体も推定するという教師なし学習です。利用場面は多く、重要な技術であり、関連研究も多数あります。トピックモデルでは、最も尤もらしい1つの結果(解)を推定するのが一般的ですが、初期状態を変えると様々な結果が得られ、しかも同程度に尤もらしい結果(解)が多数存在します(図(上))。人間が見ても明らかに異なる違いがあることから、多様な解の全貌を把握することが重要と考え、その問題を解決するための研究に取り組み、得られる解の集合を分析して可視化する方法を提案しました。図(下)の〇は、得られたトピックを集約したもので、類似するものは連結されています。直近では、この多様性を考慮した上で、トピック階層(概要から詳細まで、関連するトピックを結び付けて示す)を発見することに取り組んでいます。
主な研究業績
T. Uchiyama and T. Hokimoto, “Analysis of solution diversity in topic models for smart city applications,” in Sustainable Smart Cities-A Vision for Tomorrow, IntechOpen, pp. 51-70, 2022.
内山俊郎, 甫喜本司,“トピックモデルにおける多様な解の単語分布に基づく解析, ” 電子情報通信学会論文誌 D, vol.105, no.5, pp. 405–415, 2022.
内山俊郎, 甫喜本司,“トピックモデルにおける解の多様性の分析と可視化, ”電子情報通信学会論文誌D, vol. J102-D, no.10, pp. 698–707, 2019.
T. Uchiyama, “Information-theoretic clustering and algorithms,” in Advances in Statistical Methodologies and Their Application to Real Problems, IntechOpen, pp. 93–119, 2017.
研究室の指導方針
学生の興味や前提知識を考慮して、修士論文のテーマを決めます。大学院で学ぶ意義の1つは、教員が取り組んでいる研究に触れることと考えておりますので、教員の研究と関連するテーマを選んで頂きたいと思っています。ただし、文書データ解析に限定することはしません。データ解析に関することであれば、多くの場合対応できると考えます。

